Real-Time Messaging


Modular and portable control software is becoming a key enabler for flexible production systems in industrial automation.
Our WebAssembly-based approach provides a common abstraction for real-time and non real-time control modules through a lightweight, sandboxed execution environment. Think containerization, but fine-grained and real-time. This article dives into some of the underlying concepts. So-called isolated WASM modules, combined with real-time scheduling and low-latency communication, allow our system to achieve secure, highly portable, and resource-efficient control software.
The Need for Real-Time Data Sharing
In modern manufacturing, flexibility is no longer optional—it’s a necessity. Volatile markets and unpredictable supply chains demand production systems that can adapt on the fly. One promising approach is software-defined manufacturing (SDM), where hardware and software are decoupled, allowing entire production processes to be reconfigured through software updates.
But this flexibility introduces a new challenge: how do different software modules communicate efficiently, reliably, and in real time? When multiple processes share the same compute node, passing data safely between them becomes a complex problem, especially on multi-core processors where reads and writes can overlap and create inconsistencies.
This is where wait-free concurrent data access comes into play. Unlike traditional locks, which can block processes and even risk deadlocks, wait-free methods guarantee that every thread completes its work in a bounded number of steps. In other words, no matter what the scheduler is doing, your data access will happen predictably. For real-time systems in manufacturing, that predictability is crucial—delays aren’t just annoying, they can break machinery or ruin a production run.
Understanding Data Channels in Real-Time Systems
Imagine a production system where a CNC machine needs to send its position data to a fieldbus controller. There are two main ways to structure this communication: either you have a single shared value that’s constantly updated, or you use a FIFO queue to pass every position in order. Both approaches have trade-offs.
Shared data is like a bulletin board: the latest update is what everyone sees. If you only care about the most recent state—like the latest configuration or sensor reading—this is perfect.
FIFO queues, on the other hand, are like a conveyor belt: every piece of data matters, and the order must be preserved. For tasks like sending CNC positions for trajectory planning, missing or reordering data could have disastrous consequences.
When you consider who is producing and consuming the data, things get even trickier. Most industrial setups involve a single producer and a single consumer (SPSC). Sometimes multiple consumers or producers are involved, but as the number of participants increases, so does the complexity and memory overhead—especially if you want wait-free guarantees.
The Nuts and Bolts: Atomics, Memory, and Linearizability
At the heart of wait-free methods are atomic operations. These are the building blocks that let a CPU update memory safely without interruption. Common operations include Compare-and-Swap (CAS), Test-and-Set (TAS), and Fetch-and-Add (FAA).
But there’s a subtle challenge: modern CPUs don’t execute instructions in the order your code was written. They use caches, buffers, and out-of-order execution for speed. This means that algorithms must account for memory consistency and ensure that operations appear linearizable, or sequentially consistent, to all observers. For queues, this property is critical—if the order isn’t preserved, your conveyor belt analogy breaks down.
Caching also plays a role. CPUs store frequently accessed memory in small, fast cache lines. If multiple processes write to variables that share a cache line, it can cause delays known as cache misses. Clever use of cache padding or thread-local variables helps mitigate these issues and keeps wait-free structures fast.
Wait-Free Shared Data in Practice
How do we actually implement these concepts? Classic approaches like mutexes or reader-writer locks work, but they can block, which is unacceptable for real-time systems. Wait-free methods, like the triple-buffer technique, allow both producers and consumers to operate without ever waiting on each other.
In our experiments, we implemented several approaches in Rust—including mutexes, reader-writer locks, and various wait-free algorithms—and benchmarked them on a dual-CPU server.
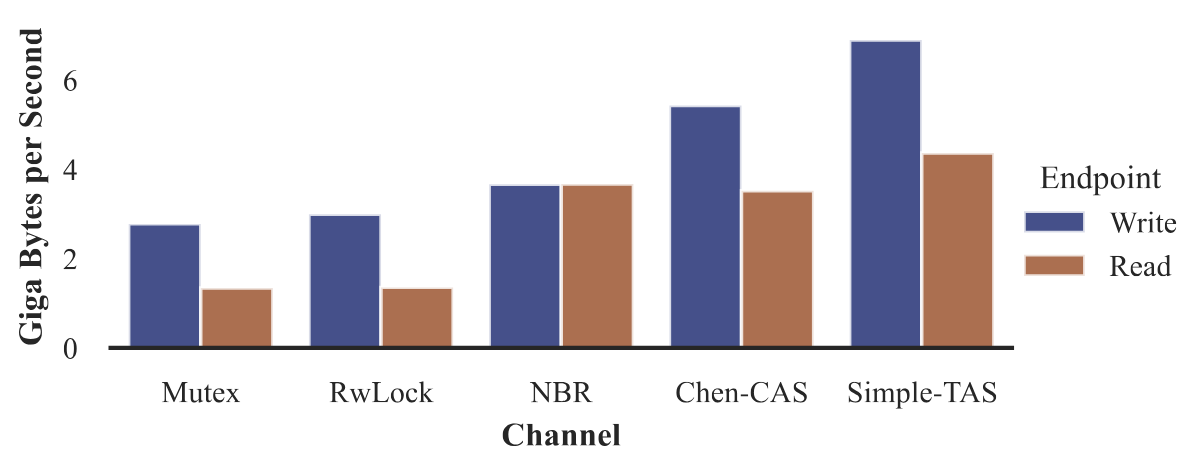 Figure 1: Throughput for different shared data channels.
Figure 1: Throughput for different shared data channels.
What we found is intuitive but important: traditional locks limit throughput because producers and consumers block each other. Wait-free approaches like Simple-TAS or Chen-CAS perform better under heavy, high-frequency access, and crucially, they guarantee that no thread ever stalls indefinitely.
When we simulated more realistic cyclic access patterns, with updates every 100 microseconds, all implementations performed well on average. The maximum observed delays were mostly due to system jitter rather than algorithmic blocking—showing that wait-free structures are not just fast, they’re reliable under real-world conditions.
FIFO Queues: Keeping the Order
Queues add another layer of complexity because order matters. Linked-list queues are flexible but require unpredictable memory allocation, which is a no-go for real-time systems. Array-based queues are faster and deterministic but need a fixed size. The FastForward queue, an array-based SPSC implementation, stood out in our benchmarks:
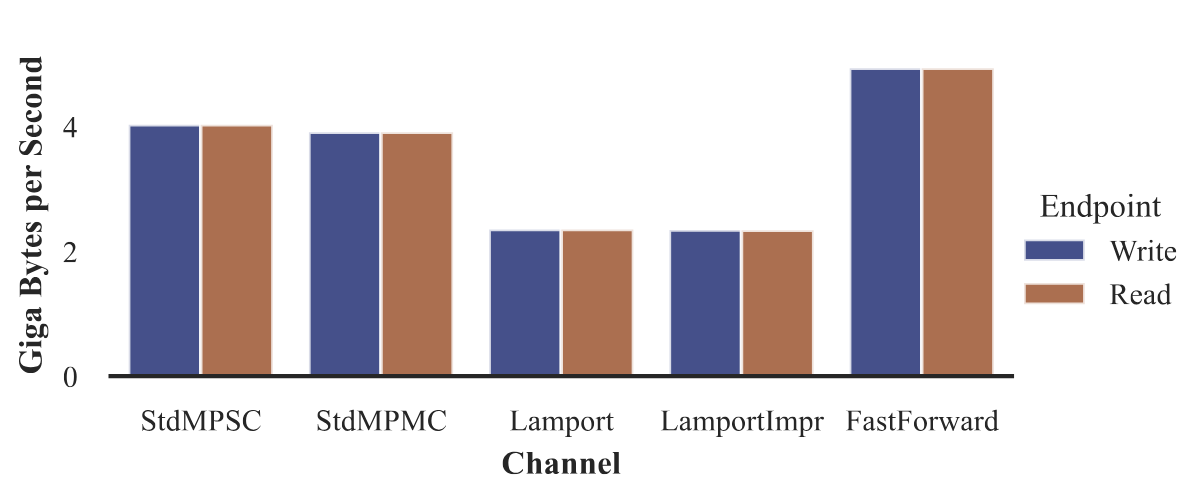 Figure 2: Throughput for different FIFO queues
Figure 2: Throughput for different FIFO queues
It significantly outperformed Lamport’s classic SPSC queue, mainly because it minimizes cache contention and uses per-slot control flags efficiently. Timing measurements confirmed the expected system jitter and median access times in the tens to hundreds of nanoseconds—well within the bounds for real-time applications.
Wrapping Up
Real-time manufacturing systems demand communication mechanisms that are fast, predictable, and safe under concurrency. Our work shows that wait-free data structures—whether for single shared values or FIFO queues—meet these requirements. Triple buffers and FastForward queues offer simple yet effective solutions, capable of handling microsecond-level operations without blocking.
For anyone designing software for modular production systems, these findings highlight that wait-free is not just theoretical—it’s practical, measurable, and ready for deployment.
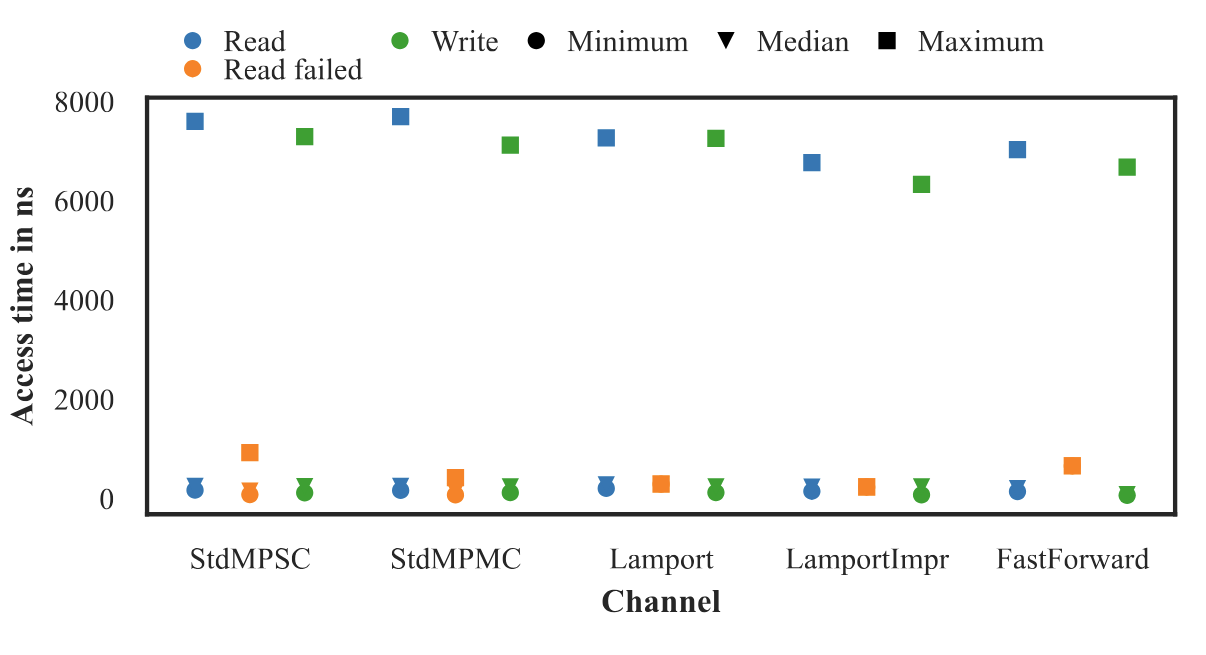 Figure 3: Timing for different FIFO queues.
Figure 3: Timing for different FIFO queues.
Conclusion and Advantages of Our Messaging API
In this work, we analyzed wait-free concurrent data structures for real-time systems, covering both shared data channels and FIFO queues. Our benchmarks demonstrate that these algorithms—triple buffers for shared values and the FastForward queue for ordered data—provide extremely low-latency, predictable, and high-throughput communication between processes.
Building on these proven algorithms, our messaging API wraps them in an ergonomic and easy-to-use interface, offering several advantages for industrial software developers:
- Abstraction of Complexity: Developers no longer need to manually manage atomic operations, memory barriers, or cache optimizations. The API handles all of these internally while guaranteeing wait-free behavior.
- Consistency and Safety: By encapsulating the underlying algorithms, the API ensures linearizability and race-free access without requiring in-depth knowledge of concurrent programming.
- Flexible Communication Patterns: Our API supports both single shared value channels and FIFO queues, allowing developers to choose the right pattern for their use case without changing the core logic.
- Real-Time Guarantees: Because the API is built on wait-free primitives, all operations complete in bounded time, enabling predictable temporal behavior essential for real-time manufacturing applications.
- Ergonomic Design: With a clean and consistent interface, integrating real-time messaging into existing control software is straightforward, reducing development time and potential for errors.
In summary, our messaging API leverages state-of-the-art wait-free data structures while providing a developer-friendly interface, bridging the gap between high-performance concurrency algorithms and practical industrial software development. It allows engineers to focus on their application logic, confident that data exchange between real-time processes will be safe, fast, and deterministic.
References
Full references available in the original publication, including works by Chen, Lamport, Giacomoni, and others on wait-free concurrent data structures and real-time systems.
Bring Real-Time Messaging to Your Systems
If your applications demand deterministic, high-throughput, and jitter-free communication, our real-time messaging framework is built for you. Designed for both real-time and non real-time environments, it delivers predictable performance without the complexity of traditional lock-based approaches. Whether you’re integrating distributed control software, connecting modules in a production line, or building data pipelines that can’t afford latency spikes — our wait-free messaging API gives you the reliability and speed you need. Ready to make your system communicate in real time? Get in touch and let’s talk about how our solution can fit into your architecture.